Sketch: Using RSS, LLMs, and Semantic Search to Follow News Topics
Introduction
After witnessing some truly chaotic political news about tariffs in early 2025, I was starting to get lost in the constant churn of changing rules and regulations being announced in news articles on a nearly-hourly basis. While an active observer could, perhaps, keep track of everything and put together a mental model of the state of the world, I found the idea of this to be overwhelming and unappealing. I wanted to be informed as a responsible member of society, but did not want to spend all of my waking time tracking and understanding the impact of each individual change. One way that a person could try to keep up to date would be to follow some news publication RSS feeds, watch out for things about tariffs when performing triage on your new RSS items, and then go back through your collection of items to extract the relevant pieces of news. None of this seems enjoyable to do by hand. And what happens if you care about more than one topic?
What I really wanted was to not spend my time cobbling together updates into a coherent timeline that kept me current. What I wanted was to have the answer to the question: what has changed today for topic X and what is the current state of the world? So why not make some of my numerous computers do this for me?
With AI tools constantly expanding around us and numerous methods like Retrieval-Augmented Generation being well-worn territory at this point, it seemed like it would be achievable to put together a few different elements: use a combination of RSS feed polling and LLMs to get news updates automatically, figure out which ones were relevant to the topics I wanted to follow, and combine the discovered articles into a daily summary for myself.
What I implemented was an initial proof-of-concept that allowed me to try out the idea. It was not a polished, production-quality system (to the extent that I don’t really want to share the code publicly yet), but after putting it on the shelf, I wanted to share some of the implementation details and architecture of the project for anyone who might be trying to understand this type of system better.
After vibe-coding an initial, basic React UI (which was definitely programmer art), I had something that looked like this:
Feeds Management
Topics Management
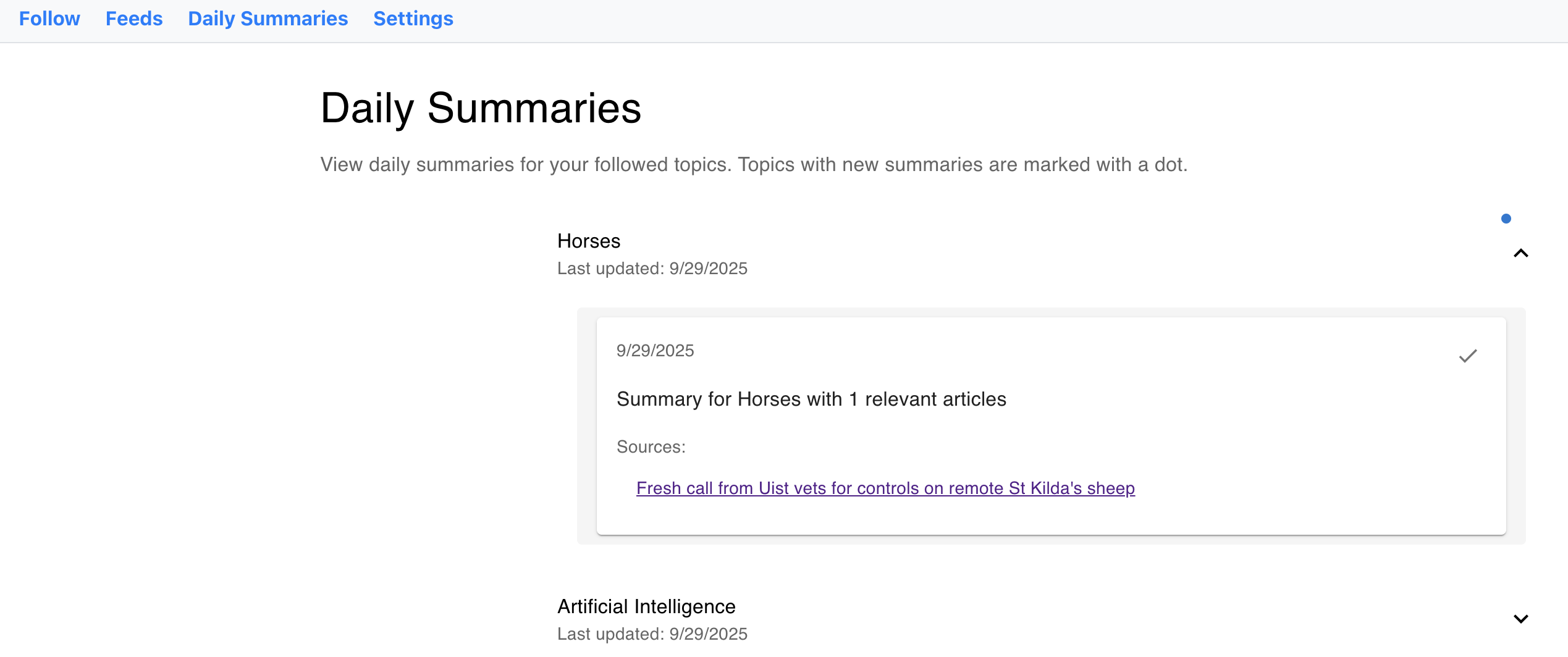
Daily Summaries by Topic
Right now, the daily summaries only include a list of the articles that would be used to create the summary. In the finished version of this app, I would want the LLM to take the contents of these articles, pull out relevant segments of the article to use as citations, and put together a full paragraph describing the day’s relevant news (replacing the text “Summary for TOPIC with NUMBER relevant articles” seen in the screenshot).
Background
In order to do all of this, there were a few pieces of technology that were needed to make the system work. I’m not going to go into extensive detail about these topics in this article, but I’ll link to more in-depth primers if you have interest in learning more. My intention with this article is not to fully explain all of these topics, but to give people a more accessible look at how you can compose some of these things into a working whole.
Vectors and Embeddings
A vector in Python is essentially just a list of numbers and can be used to represent a set of conceptual coordinates, locating a concept in “idea space”, essentially. If you imagine a coordinate in 3D space, you have three coordinate values: X, Y, and Z. In a vector used for LLM embeddings, you would tend to have hundreds of dimensions or more, which can be a little hard to visualize, but the concept is the same. As an application developer, you’ll use an embedding library to calculate your embedding vector (the representation of the input as a vector after being processed by the model). From there, you have a “point in concept space” that you can use with a cosine similarity search to find related items by drawing a similarity threshold bubble around your concept and saying “anything within this bubble is relevant to my search”. This is a way of doing semantic search, which is essentially what I wanted to do with my system: as each RSS feed item is located, I want to classify whether it is relevant to any of my defined topics or not. I’m skipping some nuance here, in that language can be complicated: if you’re reading an English sentence and see the word “square”, how do you know whether it’s referring to the shape or an uncool person?
Some good descriptions of vectors and embeddings can be found here:
- Vector Embeddings for Developers: The Basics (Roie Schwaber-Cohen, Pinecone)
- A Beginners Guide to Vector Embeddings (TigerData)
Vibe Coding Tools
I’ve been switching back and forth between a couple of different tools kind of arbitrarily just to see which one feels nicest to use as well as which seems to provide the best results. While I was working on this app, I started out using Cursor in what I would consider a “full vibe coding” setup where I just wrote prompts in the chat window and mostly took whatever code was generated. At some point, I got frustrated with Cursor getting stuck while working on a bug and I ended up switching over to Claude Code. For whatever reason (I think this also involved changing models during the switch from Cursor to Claude Code), I felt like this gave me much better results in working on whatever part of the app I had been working on at the time. Since finishing working on this project, I’ve also tried Amp and it has also done pretty well with whatever I’ve thrown at it. One thing I will mention about Amp is that I like that it is shipped as a VS Code extension rather than a fork of VS Code. This allows me to keep my setup the same whether I’m working with AI or not.
At this point, I kind of just cycle through the tools based on my feeling at the time, trying whatever people seem to be most excited about. There seems to be a building consensus about minimum feature sets for these types of tools and it feels very much like a “rising tide lifts all boats” kind of situation. Oddly, this also makes the tools pretty fungible. Each time new models are released by the major providers, the crowd favourite seems to change for a while. Whether any particular tool is “better” seems to come down to what models it has access to and whether it works in your preferred editor the way you want it to.
Application Architecture
To implement the project, I needed to choose some tech stack to work with. I chose some things arbitrarily, based on the likely ease of implementation. For others, I asked the agentic coding tool what it thought I should use, and after consideration of a couple of options, I made a choice. The code organization isn’t the best and could use a general tidy, but for experimental code, it’s not an issue. The general architecture of the app is shown below.
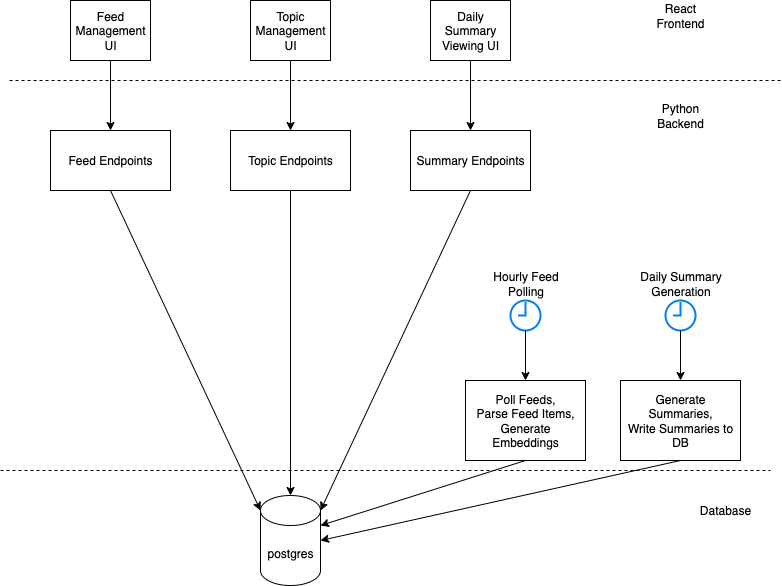
General App Architecture
This is all pretty basic, which is pretty interesting in itself. A project of this nature doesn’t really require anything alarming in terms of architecture and in my case, was only ever run locally on my (fairly old) laptop.
I chose the following for the main parts of the tech stack:
- Python and FastAPI for the backend
- React frontend
- Postgres with pgvector extension
- Backend Task Scheduling: APScheduler
- LLM Integration: OpenAI
Monitoring RSS Feeds And Storing Embedding Vectors
Ths main work of the app was done by scheduling a task to run that would iterate over a list of RSS feeds and check for any new items. New items that were located would have their content downloaded and extracted. Then a new embedding would be calculated and stored (along with their original text) in the database.
Something that you might not expect initially is that there are about a million ways to do each of these things! 😀
Content Extraction With newspaper3k
After some searching and ChatGPT research, newspaper3k was what I chose to download and extract content from the RSS item web pages. This got rid of some of the annoying work of parsing HTML and getting attributes out of it like the page title or body text. For my purposes, newspaper3k seemed to work well enough. I got enough text out of the page to compute a vector for the article, and that was really what I needed.
Choice Of sentence-transformers Model
Now that I had the content of the website, I needed some piece of software to take the text and turn it into a vector. I used the sentence-transformers Python library with the default all-MiniLM-L6-v2 model for this (the model is conveniently downloaded in the background the first time you run it). This happens to generate 384-dimension vectors, so that is what I set up the database schema to support, as well.
Postgres And pgvector Extension For Vector Storage
For this level of scale (single user, updates a few times per day, maybe a dozen RSS feeds or so), there was basically no pressure to try that hard on database selection. This is something that exclusively ran on my laptop, not something that required a datacenter or cloud-hosted database. I decided to go with Postgres and the pgvector extension mainly to get some experience with the extension. The extension allows you to use columns with a vector data type of a particular dimension that can be used to store something like an embedding as was done in this application. It also allows you to use database queries that filter based on similarity comparisons between two vectors. The extension was smooth to install and didn’t really give me any difficulties.
Generating Daily Summaries
After the articles had been collected by the first scheduled task, a second one was used to generate the daily summaries. When this task ran, it would iterate over the topics defined previously by the user (consisting of a search phrase and a minimum similarity threshold). For each topic, the app would then gather any articles stored in the database from that day that were relevant (ie. the similarity threshold to the search phrase exceeded the required threshold). While the current state of the app just provides some debug text, the next step would be to provide these articles to an LLM along with a prompt to turn the content into a summary paragraph for storage. The UI could then retrieve these summaries when requested by the user.
One alternative option that could replace a significant amount of the work done by this app would be Anthropic’s “Citations” capability that says it does almost the exact thing that I want: it looks through your reference text and provides an answer to your query with citations back in the original documents’ text. If I was making a production system, I would strongly consider using something of this nature if I wanted to focus on building my application. However, if you wanted to develop your own custom search or classification algorithms, it might be better to build it by hand so that you could tweak the behaviour of various parts of the process. For this project, I chose not to use Anthropic’s Citations API for the reason that I was trying to learn more about implementing these systems (and I was trying to avoid incurring additional costs and an additional API integration 😀).
User Interface Concept
A lot of the UI was just there to support the basic CRUD operations of managing RSS feeds and topic definitions. If this were to be promoted out of a prototype phase and into a real service, the area that would need the most work (aside from CSS styling the entire app in a more aesthetically-pleasing way) is the daily summary display. What I envisioned was a vertical timeline or “river” view, with dates appearing on alternating sides of the line (like guideposts or horizontal railway semaphor signals) followed by the day’s summary for that topic, allowing the user to read the changes over time.
For the prototype, I settled for a list of topics with a “new content” blue dot indicator. Each topic was a drop-down that could be expanded to reveal the daily summary content for the days it had been created.
AI Usage for Testing
Many people use LLMs for writing, editing, and reviewing code. LLMs and agentic coding tools can also be used to generate content that can be used with more traditional testing techniques. Postman, for example, can import a JSON file defining a collection of API tests. As a developer, one of my least favourite tasks is creating and maintaining Postman collections, however I find it very convenient to have full example requests available for reference, testing, or troubleshooting. Why not use an LLM?
Postman Collection Generation and Importing
If you’re managing Postman collections the traditional way, every time you add a new endpoint, modify request/response schemas, or change URL patterns, you need to manually update your requests and/or environments. It’s an annoying chore that can snowball over time as the complexity of your business logic increases.
Because AI agents can read and understand the functionality of your API, they can also generate relevant, correct test data rather than just generating random strings. When you update your API, you can just ask the agent to update the JSON file for Postman, then re-import it. This lets you have the benefit of a full set of manual API tests if I want to use them without investing excessive time in their creation or maintenance—1it’s a win-win.
Postman Collection
Conclusion
I enjoyed working on this project and with all of these tools. While I didn’t implement something thoroughly polished or launch a new company by doing it, side project explorations like this are a great way to learn more about the details. If a better solution was available to the content parsing and bot-blocking slog that I envisioned affecting the work on this app, it would be something I might return to in the future. I don’t know that this would be considered a valuable feature for read-it-later software, but products that already download, extract, and AI-process RSS feed content would probably have a much easier time integrating something like this into their existing systems than someone looking to make a standalone product.
One of my favourite parts of this project and the proliferation of AI coding tools is that it is easier than ever to take an idea like this and go experiment with it, turning it into a real piece of software. I hope that this article has given you a little inspiration to go out and build something of your own!
If you’re interested in this kind of system and would like a more thorough exploration of the topic (at a significantly increased scale), I recommend reading Wilson Lin’s post called “Building a web search engine from scratch in two months with 3 billion neural embeddings”.
This is a bespoke, organic em-dash. It was placed lovingly by an actual human writer. ↩︎